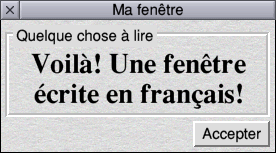
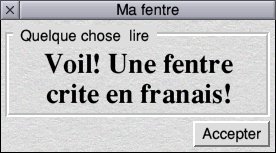
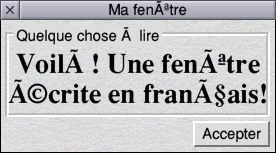
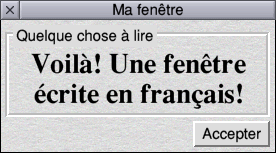
UTF-8?
![]() 153 posts, 18 voices
153 posts, 18 voices
|
|
Yup. Okay. I’m proper impressed. ☺ |
|
|
Yes, that’s very nice. From your explorations, nemo, how hard would it be to have a larger sized character set (16×16, say)? Cursor copy would be fun! |
|
|
Yes I’m way ahead of you WPB… quite obviously once one gets past Hiragana and Katakana (done already of course, arigato) trying to do even a primary school (or more sensibly, newspaper) subset of Kanji is simply impossible in 8×8. And 8×8 is pretty tiny on big monitors anyway. The difficulties in switching to a 16×16 System Font are subtle and various, but one of things I have tackled is the need to support 8×8 simultaneously and nicely. As such I’ve written a resolution enhancement 8×8 to 16×16 in anticipation of tackling the larger problems. Influenced by the enhancement algorithm of the SAA5050 teletext chip that did Mode 7 in the Beeb in fact! BFont would stay mostly as 8×8 but a new SWI would allow 16×16 definitions too for those glyphs that require it. However, there’s a significant amount of work required to support 16×16 and make the glyphs that necessitate it… and at the moment there’s really no usage case. Let’s face it, the cries for Japanese and Chinese support in RISC OS are hardly cacophonous. And I’m not volunteering to write the IME necessary either! |
|
|
I started adding glyphs to the “Default” Zap font (8×16), to extend its Unicode coverage a while ago. I didn’t add nearly as many glyphs as you’ve done though. The bitmap font is used by NetSurf’s framebuffer front end, and the data for it is available here: http://git.netsurf-browser.org/art.git/plain/fonts/netsurf/glyph_data It’s in a text format so it’s easy to see what’s changed from version to version with diff, also you could use a text editor to edit it. :) I still need to write a converter to the “wide” Zap bitmap font format (used for Unicode support). If anyone wants to add more glyphs, please get in touch. :) |
|
|
Never doubted it for a second! ;)
Personally, I’d just like to see the concept working. The CJK glyphs can be added later, either drawn if it’s a rainy day (!) or purloined from a HBF font or similar.
No, but the more support is added, the more likely it as that some Japanese and Chinese people will get interested in the OS. |
|
|
I can’t commit to implementing 16×16 at this stage. However I am working towards a release of a UTF8Support module that supports UTF-8 outside the desktop. It will include:
The first five of those are done already (though I have a few hundred more glyphs I want to do). I’ll keep 16×16 in mind, but I don’t want it to further delay this work, which has been a sizeable undertaking. |
|
|
Though I have an aesthetic fondness for the “MODE 0” aspect of 8×16 (my own Zap font is 8×18 in fact), it’s still insufficient for most Kanji (eg 魔) so I suspect that as WPB suggested, where 8×8 is insufficient, 16×16 is the obvious remedy. For aesthetic and historical reasons I’d want to keep the “BFont” style for Roman (and Roman-style) glyphs even at 16×16 – yes the text is bold but that’s how it always was. However, for 16×16 CJKV glyphs I’d be tempted to use the GNU Unifont. It would save a LOT of work and would be trivial to convert. |
|
|
That’s fantastic news. I look forward to it.
What is this to do with UTF-8? (Be gentle!)
Sure, better to release something than aim for perfection and get nothing done. (Points finger at self and waggles it accusingly…) It would be lovely to have 16×16 in the future, but it’ll be fun just to play with kana in the meantime.
Yes, why not? I’d probably fall over dead if you said you were going to hand-draw a sizeable subset of CJK yourself! I agree, 8×16 can’t work for kanji, as you’ve said. I’ve tried it in the past, and it’s an unreadable mess. |
|
|
Replacement *Cat & *Ex implementations to improve formatting. The main difficulty with UTF-8 compared with any other Encoding that RISC OS supports (ie “Alphabet”) is that UTF-8 is a multi-byte encoding. All existing code thinks that
In the case of Other commands also try to do “tabbing”, like |
|
|
Incidentally, my implementation has to deal with the mountain of code that assumes that the whole world uses Latin1 and so spits out hard-coded text that can’t be localised (to UTF-8). Consequently the code has the concept of a fallback alphabet – if illegal multibyte sequences are output through OS_WriteC et al then rather than replace them with the Unicode Replacement Character as is usually mandated, it interprets the bytes as being intended to belong to the fallback alphabet (usually Latin1 but I WILL NOT hard wire it!) and so outputs the correct characters. This has the unfortunate but unavoidable¹ side-effect that if an ‘old’ program displays Latin1 text (say) and then allows the user to type in (or cursor-key-copy!) that text, it won’t match – as it output Latin1 but input UTF-8. ¹ It’s unavoidable in that OS_ReadLine would have to know that a program was ‘old’ and switch to delivering text in the fallback alphabet… but there’s no safe way to infer that. Even if a program outputs Latin1 instead of UTF-8, that doesn’t mean the program is UTF-8 unaware, only that the data it output was… which may have been the contents of some file for example. |
|
|
Forgive me for stating the obvious, but why not add a flag to OS_ReadLine32 to indicate that the caller wants the result in UTF-8? Yes, this means software will need updating to add support for that flag, but surely most software will need updating for correctly handling UTF-8 anyway? |
|
|
Answer: Because the default ReadLineV claimant (i.e. the kernel) doesn’t actually check for invalid flags. Fantastic. Plus adding a new flag to OS_ReadLine32 won’t be very backwards-compatible with 26bit systems where OS_ReadLine32 needs to be translated to an OS_ReadLine call. So I guess the best solution is another OS_ReadLine SWI + vector, one where claimants validate their arguments properly and with a default claimant that passes on to OS_ReadLine/OS_ReadLine32? |
|
|
Because most code is actually encoding agnostic, and UTF-8 is merely one such encoding – what about ShiftJIS, Big5 etc? Do we have bits for each of them too? No, that’s what the Alphabet is for, and it’s perfectly possible to change it around a call to ReadC, ReadLine etc, so the call doesn’t need encoding options, the OS already has that. If you’re calling ReadLine you’re most likely to take the result and use it atomically, and there’s very little problem. If a program is known to have problems, then that program needs to run under an 8bit Alphabet. Whether that is done manually or automatically, it’s not something that needs to be done on a per-call basis. It may be more sensible to have such a setting per Task under the Wimp, as it is in a much better position to switch Alphabet as it goes (if necessary) and, as it’s not a particularly lightweight operation, it would make sense to group those tasks that require it. However, the majority of Tasks are also agnostic. What is intolerable though is having the desktop and command line disagree about what a file is called. That’s not workable. That’s why I did this work. Sadly, emulators such as RPCEmu (or rather their host-side HostFS implementation) will have to be updated to map host filenames to the current alphabet instead of the hard-wired lossy conversion to Latin1 that they all do at present. |
|
|
No, really no. There are a shed load of calls that currently implicitly require the current Alphabet. Many of them are broken to some extent with regard to multibyte encodings (I haven’t looked at PrettyPrint yet, but obviously it should split words at Unicode whitespace, not just character). We do NOT want to switch to encoded versions of all of those. That’s what the Alphabet is for already. It’s also not the solution that anyone wants, as no one wants to input one line of text (at the command line) in UTF-8 then the next only in Hebrew, somehow causing IME/Keyboard Layout to change automatically and all associated code to switch too… if you want to do that, change the Alphabet (but switching keyboard layouts to suit the program rather than the user is a terrible thing to do). This is an exercise in enablement and compatibility. Introducing new application requirements is completely pointless. |
|
|
So why doesn’t your code use the current Alphabet to determine whether it should be treating input/output as UTF-8 or not? :-) |
|
|
nemo, does the system alphabet have to be set to UTF8 for your module to do anything? Also, when putting UTF-8 into the keyboard buffer under your module, do all top-bit-set bytes have to be preceded by a zero, as was always the case back with the BBC Micro? |
|
|
That’s hard enough to see on an LCD (13×12) with coloured hinting. I’m always impressed that eastern Asians can read it as fast as it scrolls along the screen. Must be a heck of a lot of mental processing going on…
We really need a set of fast OS calls that can do string length/split point (etc) in UTF-8. Luckily due to the design of UTF-8, there’s no need to parse the character to work that out (for a fixed width). Simply check that the UTF-8 sequence is valid (and if it is not, just assume Latin1).
? If we keep clinging to the past, we’ll never advance into the future. There are many many changes from the Archimedes era to the modern SoCs; modern systems won’t run 26 bit code period. Most older systems can’t run 32 bit code. The only safe thing is a subset of the instruction set that doesn’t attempt to switch processor mode, doesn’t attempt to do anything with flags that can’t be done as a mathematical result, and doesn’t attempt to load words from non-word addresses.
Oh. The only way this is going to work in the long run is to make UTF-8 the default and anything that is not be dealt with by some sort of compatibility option. Including it as an “add on” means that only certain people (that can spot a kana from fifty paces) will use it, everybody else will do sweet fanny adams ‘cos that is the easier option. Hence acceptance/use will be low and you’ll wonder why you bothered. Now, I’m not asking for UTF-8 support just so my songs can be named correctly. That’s a side effect. I’m asking for UTF-8 support because this is an area where we are badly lagging behind. The lack of anything other than a fixed defined 256(-33) character character set is simple to deal with, but is in danger of being an anachronism from a gentler more innocent age where pretty much the extent of regionalising stuff would be to misspell “COLOUR”. |
|
|
But how can you tell that something isn’t UTF-8 aware unless it has a way of telling you that it isn’t UTF-8 aware? As far as I can see we have several options:
On a hypothetical UTF-8 only kernel we just make OS_ReadLineUTF8 the default and make OS_ReadLine/OS_ReadLine32 throw an error. Problem solved. You even said yourself:
And yet you want us to cling to OS_ReadLine/OS_ReadLine32, two completely terribly defined SWIs? |
|
|
I think the point nemo was making is that you don’t want to start getting into the realm of passing strings in differing encodings around the system at one time. I think it’s better to assume that the system alphabet is that set by *Alphabet and don’t complicate it. At a task level, rather than an API call level, there’s the possibilty of running things with different encodings, but it’s prone to problems. Ben’s already pointed a lot of them out. But basically any text IO has to then transcode, and that’s generally going to be a lossy operation. It does work – I’m doing it with MPro at the moment – but it’s messy, and you end up having to introduce a load of user options saying, “Convert to/from UTF-8 when doing x” (e.g. User receives a UTF-8 encoded email, wants to reply and edit using an external editor, which may or may not support UTF-8. What do you do with the original message which you typically quote with “>” and put into the reply? You have to transcode to {system alphabet} and lose information, even though when the reply is then actually sent, you may well send it UTF-8 encoded again.) What, IMHO, we should be working towards is making the default system alphabet UTF-8. It’s not all that hideous if you set it to UTF-8 at the moment. Resources files for apps obviously need transcoding. We discussed that fairly recently when Rick developed his ResFinder tool. I argued for having a separate UTF-8 location for resources so that Latin1 encoded (or really, system-default encoded) resources can exist alongside UTF-8 resources, and the OS/ResFinder tool can pick the most appropriate to match the system alphabet. If the alphabet is UTF-8, but no UTF-8 recourses exist, fall back to Latin1 and it’s not THAT bad. No worse than what happens at the moment if you do *Alphabet UTF8 in fact. The Wimp’s text icons should work properly with UTF-8. Toolbox needs updating, but that shouldn’t be too hard. What will break the most are apps that do a lot of “proper” text manipulation (not using icons, I mean). They’ll have to be updated, or be lost, or only used by people who don’t have their alphabet set to UTF-8 – but that’s the price of progress. (Actually, I don’t think the Wimp does behave correctly with UTF-8 encoding text in icons unless the system alphabet is UTF-8. In other words, setting the encoding of the font in use in the icon – with “\EUTF8” in the font specifier – gives you UTF-8 output but the Wimp tramples all over codes that look like the special characters it uses, like the upwards arrow to indicate shift-keypress in menu entries, etc. Clearly this is just done naively with a context-insensitive search and replace algorithm unless the system alphabet is UTF-8, when the Wimp should really be checking the encoding of the font being used in the particular icon in question. I fixed this with a mod to the Font Manager that disallows mid-string font changes if they occur inside a UTF-8 sequence – as they are conveniently illegal UTF-8 constructs. It’s not the “right” fix, but it does solve the problem, and also solves the problem on RISC OS 4/6 if the UCS FM is softloaded, which is handy.) Anyway, this is starting to become a ramble. Main point: I believe we need to work towards making RO5.2-something have a default alphabet of UTF-8! |
|
|
Not really. I’m wondering if something different, more capable, and expandable, could be devised instead of a different incarnation of OS_ReadLine? Certainly, I would imagine an application can do better than OS_ReadLine(32). I mean, what’s the deal with the password replacement character and the upper/lower acceptable range? 1 #BitThirtyOne + BitThirty ? <sigh!> |
|
|
Not necessarily. The simple way to fix a LOT of issues is for the system to include code to “assume” that invalid UTF-8 sequences are instead Latin1. [http://en.wikipedia.org/wiki/UTF-8#Invalid_byte_sequences] If this is done, we can switch to UTF8 and pretty much everything that uses Western European languages should still work as instead of displaying nothing, it will fall back to the Latin1 character. From my blog:
If the automatic fallback is for Latin1, then all but UTF8-on-Latin would look alike. Which would be A Good Thing. |
|
|
The challenge is to make sure that software that assumes Latin1 will run correctly. Otherwise it will cause problems. After all it would be silly to cater for obscure foreign characters for a tiny minority of people at the expense of the great majority who do not need them. |
|
|
Yuck! Yuck! Yuck! [source] That makes my head hurt! |
|
|
Jeffrey asked
It does, but you’re missing the point. If the user has chosen Alphabet UTF-8 then they want Unicode. The majority of software will be unaware that there is such an alphabet (or will do the usual of assuming Latin1) and so will do one of the following:
However, a small number of programs will try to do one of the following things:
These programs will need to have the alphabet switched (perhaps by some handy compatibility module) to still do something useful (though only really if you happen to use Latin1). NONE of these scenarios are fixed by having ReadLine have a UTF-8 flag. WPB asked:
Yes, and the intention is to support that alphabet for versions of RO that don’t already have it (though the desktop wouldn’t work without newer modules anyway, but anyway).
That’s a buffering implementation issue and is unchanged. Rick observed:
I completely agree, which is why I’ve taken this approach – feed UTF-8 into OS_WriteC and you get the correct characters on screen. Feed Latin1 in instead and by the magic of clever you get Latin1 out… unless you overpower this clever with your own clever.
Yeah. :-( This is no longer the case. :-) Jeffrey persisted with:
No, this really isn’t an issue with ReadLine. A program that makes hard-wired Latin1 decisions about text is going to get things wrong with many many different SWIs and algorithms, from Font_StringWidth to OS_Byte138. It is not ReadLine that needs tweaking in this case. WPB displayed a deep understanding of the problems summed up as:
Yes, and though the desktop clearly needs some further work and some individual Applications will need a major overhaul (or the Wimp-implemented 8-bit Alphabet switch previously mentioned) the use of UTF-8 in the desktop is mostly a solved problem (because most code is pretty agnostic and anything using outline fonts isn’t formatting by counting characters and inserting spaces anyway). No, the big problem and the (IMHO) surprising omission was the complete lack of support outside the desktop. For many platforms that will be irrelevant, but for “desktop computer” use it remains pretty essential, and we don’t want to end up with the mess that Windows exhibits (which, despite Rick’s assertion, doesn’t cope with Unicode characters at the command line unless you use PowerShell). Rick asked:
Yes that’s totally irrelevant really. When in UTF-8 mode I treat 00-FF as meaning “anything goes” and anything else as basically an ASCII filter. As Rick says it’s not much use beyond that, and code should police its own input.
That is what my code does, though it has a configurable Fallback Alphabet rather than being hard-wired to Latin1. In fact (and quite obviously when you think about it) once you start using VDU23 the character set becomes unique anyway – and yes, I do support VDU23. So in effect the “UTF-8” I implement is actually Unicode from U+0100 and up, but whatever has been programmed using VDU23 from &20-&FF.
That reminds me, when in UTF-8 ReadLine’s R4 is actually a Unicode. |
|
|
Whoa… Wait… When did I say that? You misunderstood me – the Windows command line, at least for XP, is utterly and totally incapable of dealing with Unicode. I watch my videos using SMPlayer which is a (nice) front-end to MPlayer and, thankfully, has an option to revert to passing 8.3 filenames on the command line to MPlayer, because really nothing works if the filename is ????????.mp4 and the other filename is ????????.mp4 and nothing actually called ????????.mp4 exists. Oh, and don’t expect logical results if you try to |