UTF-8?
![]() 153 posts, 18 voices
153 posts, 18 voices
|
|
I shall be impressed if/when filenames and fontnames can use non-Latin1 characters, and might well use them – but it’s not something that really bothers me. What does bother me isn’t the names of my files but their contents, compatibility of the contents with non-RISCOS systems, the ability to write text in one typeface and get the same characters if I change typeface, and the ability to write text in one application and get the same characters if I transfer that text into another application. Finally, I’d like to be able to type in any language using the standard keyboard layout for that language – with a quick and easy way to switch languages (probably point and click on a menu – I have this for RISCOS 3.7 on my Risc PCs). (I say “any language” and of course I can’t type in any language – just a few Latin alphabet languages, Russian and Hindi – but I have friends who’d love to be able to type in Greek, Armenian, Vietnamese and Hebrew…) |
|
|
Resources files for apps obviously need transcoding. That’s a nice result, and would be a great thing to have during the transition phase to encourage more people to make the switch, but feels like a bit of a bodge. I suppose it’s in a similar vein to my FM bodge that fixes corrupted UTF8 strings from the Wimp’s invasive codepoint hijacking with ⇑, etc. In the end, it would be better to actually supply resources in the right encoding for the OS, but this is a great way to fix the problem in the meantime! At what level did you implement this, Rick? Within the Wimp? Does any of the code that reads text from Template files, etc., go via the vectors that nemo’s code operates on? In other words, will nemo’s code have this affect within the desktop anyway? (Edit: Maybe you already answered that with this comment: “Yes, and the intention is to support that alphabet for versions of RO that don’t already have it (though the desktop wouldn’t work without newer modules anyway, but anyway).” – is that what you mean by this?) |
|
|
I agree that we don’t want to break too much if we don’t have to, but I believe we should be looking to encourage MORE users by supporting something users of other systems probably more or less expect as standard. Sooner or later it’s going to touch YOU (Lord Kitchener style), even if it’s just because an acute “e” in a filename is encoded as UTF-8 on another system and you want to transfer the file. (And anyway, in the RISC OS world, I’m not sure how much of a tiny minority it is, actually. Mention Japan on these fora/forums and the world and his dog seems to jump up with an “arigatō”, a bizarre seiza-based konpyuta-gengo illustration, or a Princess Mononoke reference! ;) ) |
|
|
The thing is, we can’t rely upon proper UTF-8 conversions from the outset, we can’t expect everybody to change overnight (older apps might never be updated), and there is as yet no official way to support UTF and non at the same time.
That’s the thing with UTF-8 – the trick is not to fear it. |
|
|
Well they now can (with this code). However, I primarily use emulators, so I want RO and the Host OS to agree on what files are called. THIS is the primary reason I began this. (or maybe proving Rick wrong! ;-D). Unfortunately, emulators currently map the Host’s UTF-8 to Latin1 and a lot of ?s – this will have to change.
All of which is a great advert for UTF-8… providing one has applications that support it. I think once we have the desktop AND the command line supporting UTF-8, it’s worth authors updating their apps to support it too. It won’t happen the other way around!
Well that’s a different question, and keyboard drivers are indeed close to my heart. However, there’s previously been a close coupling between the Alphabet and the Keyboard Driver that supports it – unsurprising as there aren’t many ways of typing Hebrew for example. But once your Alphabet is UTF-8, it ceases to imply any particular input scheme or IME. This is an area that will need much improvement, and certainly it’s IMPOSSIBLE to write Japanese for example without a sophisticated dictionary-driven IME. RO will need to address that, but let’s get UTF-8 and some applications working first. Incidentally, the CerilicaAlphabets module implemented a load of additional Alphabets including WinAnsi and MacRoman, and this was before Unicode was implemented in any way on RO. So I added an International Service Call to allow the keyboard driver (Cerilica’s MMK driver in this case) to get accent composition tables and the hard space code so that the same dead-key accents would work to the best possible extent regardless of the Alphabet chosen. Unicode is a better solution so I’m glad the system now uses that. More sophisticated IMEs are therefore possible. RO keyboard drivers have always supported the typing of international dialling codes to switch Country (and hence Alphabet)… but in the light of UTF-8 that’s now the wrong model. We’ll need some way of switching IME, but that’s something to solve once we have a number of IMEs. |
|
|
If anyone is willing, I’m prepared to put my money where my mouth is for this. I’m interested for the Arabic support. |
|
|
Indeed, a fact of which I’m very well aware.
As long as Draw, Zap and NetSurf support it, I shall be happy! But of course I understand that other folks will want other apps.
Except that one could pretty easily write one’s own keyboard handlers in the past, using IKHG. This was vital for touch-typing Hindi, and incredibly useful for those academic journals, allowing me to set up all sorts of keyboard shortcuts for common superscripts, subscripts and all sorts, and allowing the use of floating accents, which saves lots of keystrokes/mouse clicks. Writing one’s own UTF-8 keyboard handlers will be even better, of course – I trust we’ll be able to do it. (My son, then aged 14, did a contract (originally offered to me) for a Microsoft Fellow, writing Windows keyboard handlers to generate Unicode 16-bit codes from a loony keyboard with literally dozens of extra keys for foreign languages. We still have the crazy keyboard – I should post a photo of it! Writing Windows keyboard handlers is a nightmare compared with using IKHG – I hope we’ll be able to have something at least as good for RISCOS 5 eventually…) Dead-key accents are good – but floating accents are better. They’re basically the same, except that the accent appears as soon as you type it, and the letter then appears when you type that. Ideally, the accent would immediately automatically reposition itself if necessary to suit the letter – the system I developed for the journals left accents floating high until later, when a little app tidied them all up, as well as doing various other bits of housekeeping. I don’t know Japanese (or Chinese, or Korean) at all. The only Indic language I know is Hindi, but I understand how the typography works in all of them. Also in Vietnamese, although the multiple accents defeated my floating accent scheme 8~( |
|
|
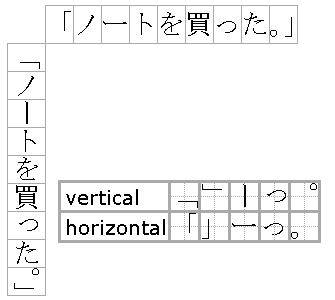
One of the complications of Japanese (and I would presume this applies to Chinese as well) is that there are two reading directions in use, frequently at the same time. The traditional way is top to bottom starting from the right. Here is a small example of both:
Original here: http://www.heyrick.co.uk/random/otome-fami_p044.jpeg 1 While the Kanji/Kana remain upright, the complication arises from the fact that Japanese has various typographical symbols such as 「quotation」 『marks』, full stop。, comma、, ellipses…, prolonged vowel(katakana) ー, and so on are rotated and their position subtly altered. These are not separate “sideways writing” glyphs. They’re the same character. Wiki has a nice graphic that demonstrates this:
I’m not an expert on this. I just 1 See also: http://www.heyrick.co.uk/random/otome-fami_p075.jpeg |
|
|
That much I was aware of. The rotated glyphs would have to be separate characters in old Acorn world, but at least it wouldn’t be too difficult for an app to be aware of when to make the substitution. On the other hand, while vertical character widths are specified in the font file format, I don’t know whether they were ever actually implemented anywhere – FontEd certainly didn’t implement them – and there’s no indication that you can choose between a vertical and a horizontal displacement: if both are specified, the inference would be that both were required, ie a sloping baseline. |
|
|
By “at the same time”, we’re really talking about “on the same page”, aren’t we? I can’t think of any examples of the direction changing within a single paragraph (though there may well be some esoteric cases). At least Chinese doesn’t have furigana, which in some ways is like ruby text (if that’s the right term). I don’t know if support for rendering such things belongs at Font Manager’s level, really. I wouldn’t naturally have assumed it does, but what do the experts think? ;) Anyway, this is really no longer anything to do with UTF-8, and more a long list of deficiencies of the Font Manager. When nemo makes his UTF8Support module release, hopefully we’ll pull things back into focus! |
|
|
Following discussions yesterday evening, I’ve just implemented vertical metrics in my !XP1FontEd, following the font file specification in the PRMs. I find that although Acorn’s FontEd can’t generate vertical metrics, it displays them perfectly happily. I’ve not investigated whether any apps take any notice of them yet. |
|
|
I believe that that’s the right term; you can at least use the <ruby> HTML element to produce things like 漢字 so it seems like the right term, at least from that perspective :) |
|
|
This requires more than UTF-8 of course, it requires a compositing text shaper – an implementation of the BIDI algorithm. I’ve never found one that works well with mixed LtoR and RtoL text (because of the ambiguities at direction changes), so I’m not convinced that a BIDI command line would be a pleasant thing to use… but I’m not an authority. All my code does, as illustrated by the screenshots, is reproduce Unicode characters in isolation. Composition is a much harder problem, not suited to the command line, and well beyond the capabilities of the Acorn Font Format at the desktop. |
|
|
Well, my phone does ruby. It just doesn’t do it correctly (unless your markup is wrong?).
|
|
|
Furigana and ruby in general needs quite a sophisticated shaping algorithm because it necessarily has to adjust character spacing to make room for the associated ruby. Once you try to implement that in a WYSIWYG editor, the editor needs to be extremely intelligent to make sense of the metrics it gets back for various strings, substrings and individual characters if it is to correctly infer things like cursor position, selection models etc. This is traditionally a weakness of BIDI implementations too. As it happens there is an OpenType table to document the virtual cursor positions within composed (substituted) ligatures, for example. So if your text is “suffix” but the font substitutes “suffix”, then the cursor can be placed within the ffi ligature. This is of course especially important for scripts such as Arabic, and any font that has extensive stylistic ligatures such as Zapfino. |
|
|
I like that…we didn’t substitute ligatures until the final (automated) tidying up immediately before printing, for precisely that reason. (And to avoid search failures.) |
|
|
Unicode defines a huge range of combining diacritics, but also for historical reasons it has a large repertoire of precomposed accented glyphs too. A UTF-8 keyboard driver ought to prefer the latter, but fall back to the former where necessary. My keyboard drivers for Windows and RO generate stand-alone diacritics in such cases, as combining accents are rarely handled properly. For example Alt-Shift-minus O emits U+014C Ō whereas Alt-Shift-minus K emits U+00AF U+004B ¯K – I don’t currently emit combining accents because so few systems cope with them well: Compare the precomposed Ō with the combined ̄O for example. |
|
|
This is what the OpenType GPOS table is for – it allows diacritics to be placed contextually allowing for other diacritics… though that’s usually unnecessary because the GSUB table will already have replaced that sequence with a precomposed glyph. |
|
|
No you haven’t, you’ve implemented two dimensional horizontal metrics. The Acorn Font System has no concept of vertical text so it does not have vertical metrics. The best you could do is create a font that has vertical-only advance widths… but since no software will be expecting that the cursor positioning, selection algorithm and probably redrawing will be highly compromised or broken. Under RISC OS you’d be better off creating a rotated font and set it at 90˚ – at least the applications might be able to cope to a better extent. |
|
|
I mentioned Zapfino in passing, but it’s the sort of font that simply can’t be encoded in the Acorn Font Format, even if you wanted to. The power of OpenType’s contextual and discretionary glyph substitution is illustrated by this image:
Just check out the number of different ‘f’ glyphs – they are all the same character. |
|
|
I’m not sure why you say it doesn’t have vertical metrics, since it has vertical advance widths and vertical kerning; nor why you can’t have both vertical and horizontal metrics (at some fixed ratio) to achieve a diagonal baseline. On the other hand, this I can well believe:
I’ve never had occasion to try actually using anything but horizontal text, or rotated text. We produced high quality academic journals and never needed to… 8~) – we did need to do international (all the Latin alphabets, plus Greek and Cyrillic) author’s names and addresses though, and on one occasion we actually had an entire page of Hindi text to set.
Probably true. Draw does 90˚ (or indeed any angle) text okay(ish) – but if I remember correctly, it ignores kerning tables 8~( – I don’t recall trying angled setting in any other app. Likewise, you could do glyph substitution in AFF, but I grant you it wouldn’t be elegant or easy to set up, and you’d have to cheat on the encoding of the extra glyphs – very non-UTF-8. Once set up, it’d be smooth enough in operation – I’ve done very similar things. How easy is it to set up OpenType’s glyph substitution for a font? (I don’t know. I’m not prejudging anything.) (Actually, looking at the ’f’s in that piece, I only see what could perfectly well be one ‘fi’ lig, one ‘f’, one ‘ffl’ lig, and one ‘fl’ lig – we had all those substitutions in all our journal fonts…not as fancy, but they could perfectly well have been so. A couple of other characters also display differences, certainly…) |
|
|
Hi Clive! Famous or not, it’s nice to have you here! ;) Have you uploaded your updated FontEd anywhere? |
|
|
No it doesn’t. It has two-dimensional horizontal widths and kerning. Both the X and Y offsets are used simultaneously. It does not use X during “horizontal text” and Y during “vertical text”, it uses both X and Y and has no concept of vertical text.
No, Zapfino has hundreds (nearly 1000 ISTR) “ligatures”, including the word “Zapfino”! The contextual substitution ensures that it doesn’t need thousands more, since it can select an appropriately shaped letter to avoid clashing with the following (or previous) letter, rather than needing a separate glyph for every combination of letters. It has nine different versions of the letter ‘d’ for example. |
|
|
Yes, I understand that. Is it actually Acorn Font Format that has a concept of horizontal text, or is it the apps? As far as I can ascertain, AFF has no concept of either horizontal or vertical.
I thought what I wrote made it perfectly clear that I’d conceded that point. “Grumpy and arrogant” surely is an apt description, I’m sorry to say. Obviously it’s nice if the font management itself can do such things, but you CAN do such things on AFF (within the limits of available memory for the font), albeit only with an extra homespun app to do the substitutions. That was a good solution in the 1990s! It took more work to achieve quality, but the quality was very high given that work; and I concede (again) that the possible coverage of foreign languages, while wide in horizontal languages, is very likely pretty poor or even hopeless in others. |
|
|
Um… Can I stick my hand up without getting shot at? Should I wave a little white flag? ;-) Elementary level question, as this is really not my area of expertise1 – what do you mean by a stroked font vs a filled font? I was always of the impression that an outline font (RISC OS or Windows, etc) was sort of like a draw file that represented the character and thus could be scaled and drawn without obvious resolution loss on screen or printer at a variety of sizes. Obviously a font contains much more information, such as character width and character width relative to others (kerning), and as is being discussed, rotational repositional information for text that can run in different directions. Possibly even smarts such as only holding one acute accent, and applying it to the characters that need it (like ‘a’ plus ` equals à). Is this woefully incorrect? 1 Hmm… <thinks> Do I even have an area of expertise? |




{kind=link}
{kind=link}
{kind=link}
{kind=link}