Some naive questions about CPUs
![]() 10 posts, 4 voices
10 posts, 4 voices
|
|
The recent flurry over Spectre and MeltDown seems to have got people wondering about open-source CPU design. I know that the design, testing and manufacture of CPUs is extremely expensive. That means that investment inertia makes it hard for radically new approaches to be tried out. |
|
|
I would imagine the sort of things you are asking about (checking multiple registers in one go) would be an SIMD instruction – maybe NEON can do that? |
|
|
What I am hazy about is what simultaneous actions a CPU can do. I am thinking of a lower level, microcode perhaps, than the instruction set. It is not so much vector operations, as n-ary operations OR and AND for a whole collection of n registers. But I am not sufficiently well versed in the physics to know what is feasible and what is not. You can obviously do a lot with vectorizing, once you know that there are no clashing dependencies: I guess that the parallellizing of data manipulations is a doddle compared to parallellizing loads and stores. I do not know how this is done. Multiple buses? [Should that be busses? buss = kiss , if that is the etymological origin.] A propos doing stuff in parallel, BBC BASIC V introduced array operations. In particular Acorn introduced componentwise multiplication |
|
|
Citation needed :-) I think there are two areas to take into consideration – the silicon and the architecture. Working with cutting-edge silicon techniques may be costly, but new architectures can be tested out very easily thanks to FPGAs, CPLDs, and software simulations.
Yes.
This is what’s referred to as a load/store architecture, and Wikipedia informs me that the first instance of such a machine was the CDC 6600 from 1964.
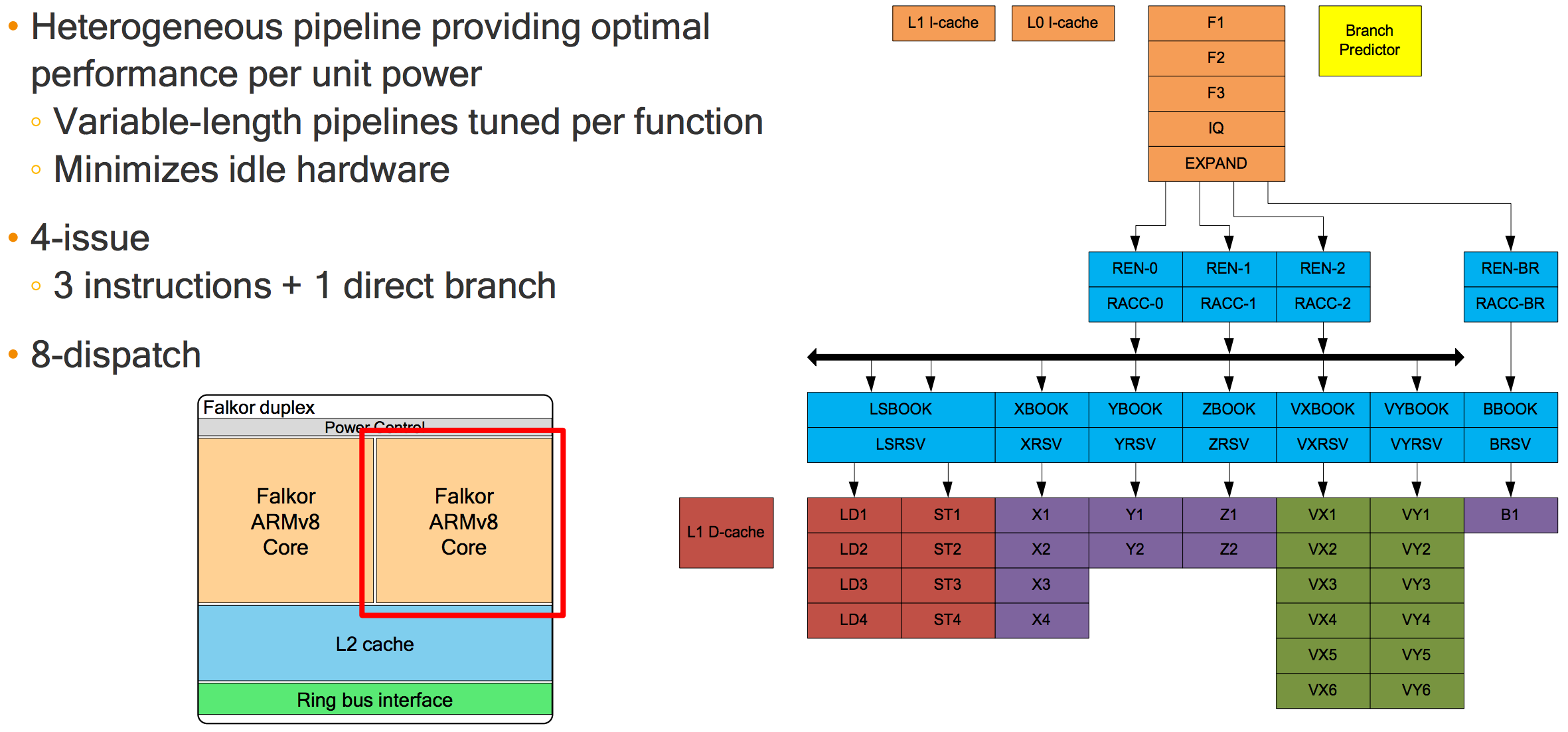
Basically, count the boxes. https://regmedia.co.uk/2017/08/20/qualcomm_centriq_pipeline.png Modern CPUs have long, branching pipelines containing multiple execution units, each execution unit essentially implementing a different microcode operation. The execution units themselves will typically be pipelined as well (so they can keep up with a sustained throughput of 1 instruction per cycle), or there may be multiple instances of the same unit (either to allow higher throughput in the face of non-pipelined execution units, or to allow for superscalar architectures where you want to be able to issue multiple instructions per cycle). Hazard detection is used to make sure that instructions are only allowed to proceed to the next pipeline stage once all of their inputs are available (specifically, the results of previous instructions). Out-of-order execution and result forwarding can help to avoid some of the stalls that this introduces (result forwarding typically allows a cycle to be shaved off of a stage, by e.g. forwarding the result of an ADD instruction straight to the input of an LDR, avoiding the need for the LDR to wait for the value to appear in the register file).
Modern internal busses & memory busses are typically based on a message-posting system rather than a one-at-a-time locked bus approach as used in the past. So a load instruction will fire off a message asking for data to be loaded (probably with an immediate synchronous response to let it know that the request hit a valid peripheral?), and then at some point in the future it will get a reply back containing the data. During the intervening time the bus can be used for other messages. To take advantage of this, load/store units will contain some kind of FIFO or queue to allow multiple outstanding operations to exist, hazard detection logic to make sure requests are performed in-order where necessary, and logic for handling other optimisations such as the ability for loads to peek at posted writes.
Which is one of the advantages of ARM’s licensing model – you don’t get a CPU, you get the source code to a CPU. Vendors can then tune the instruction set to their liking, by adding new application-specific instructions, or removing little-used ones to save on die space. And for us ordinary people, there’s FPGAs. |
|
|
You can find the papers on Meltdown here and Spectre here I still didn’t study the papers in total. The possibility given for an attack is due to the capability of speculative execution (like out-of-order execution). There’s also a chapter that addresses ARM/AMD, citation => We also tried to reproduce the Meltdown bug on several ARM and AMD CPUs. However, we did not manage to successfully leak kernel memory with the attack described in Section 5, neither on ARM nor on AMD. The reasons for this can be manifold. First of all, our implementation might simply be too slow and a more optimized version might succeed. For instance, a more shallow out-of-order execution pipeline could tip the race condition towards against the data leakage. Similarly, if the processor lacks certain features, e.g., no re-order buffer, our current implementation might not be able to leak data. However, for both ARM and AMD, the toy example as described in Section 3 works reliably, indicating that out-of-order execution generally occurs and instructions past illegal memory accesses are also performed. |
|
|
Many thanks for this Jeffrey. It gives me some pointers (and acronyms) to follow up. I was interested in your mention of message-posting. I remember reading an article in Byte magazine in the early 1980s describing data-driven processors which were essentially a network of nodes that sent and consumed messages. I guess it is a bit like the difference between wiring looms in cars as they used to be and as they are now. I remember buying a weighty, but fascinating, book, Introduction to VLSI , by Carver Meade and Lynn Conway in the bookshop of Columbia University in 1983. That should be an indication of how behind the times I am. Any suggestions for a more uptodate replacement? |
|
|
The obvious problem here is to define what you mean by CPU. While at a block level they are all the same, there are as many types of processor as there are languages… In a modern design, as Jeffrey has explained, there may be such things as dual issue execution, in that the processor can execute two instructions at the same time as long as there are no dependencies (if you load a register and then add one, it must wait; but if you load a register and add one to a different register, it can do them together).
It may be that multiplying an array by another array isn’t the most useful thing, but how about adding one array to another? Some programming constructs are different to pure mathematics, consider drawing a Mandelbrot or compressing an image?
Apparently in my S7 Samsung tuned the Mx cores for much greater efficiency and so they can go at some extraordinary speed. Apple did a lot of work on their processors. That, I guess, is one of the great advantages of ARM’s licencing model – while they are all broadly compatible with each other, it isn’t necessarily an off-the-shelf part, like the x86 family. If you can bake silicon, you can customise the ARM core… |
|
|
No problems with that, nor with multiplying the array by a constant value; nor with multiplying two arrays componentwise and then summing the results. I take your point about the haziness of the word CPU . Obviously the silicon-bakers may be faced with decisions and compromises when it comes to implementing very specialised instructions. But I would have thought by now there must be a fair amount of agreement about which algorithms are fundamentally important for general purposes. What I am still hazy about is how you can load/store with different memory/cache addresses simultaneously. |
|
|
I’m not sure you can on a traditional style general purpose processor, as the address and data signals can only hold one state at any given time, however…
Added together, these things may give the illusion of doing loads or stores in parallel.
I very much doubt that. In this day and age, any such innovation is going to get buried under a metric tonne of patents, trade secrets, blah blah. Right now everybody is obsessed with speed. I wonder if we aren’t going to see a shift in emphasis to be willing to sacrifice blazing speed for better security. Our computer hardware is often woefully inadequate. Until recently it was easy to attack the operating system, but as security there improves, the inherent weaknesses in the hardware are being examined for possibilities. Spectre and Meltdown are simply the latest ways to abuse hardware for interesting results. |
|
|
Memory attributes are also important – at the most basic level, you can use the page tables to flag certain physical addresses as being “normal” or “device”. “Normal” memory allows all accesses to be performed asynchronously; the CPU can speculatively read from it in order to prefetch data for the cache or for specific instructions, and it doesn’t need to wait for confirmation of any writes. It also allows for accesses to be performed out-of-order (except that e.g. if a program writes to an address and then immediately reads from it then the old content of that location must not be visible). The fact that Normal memory is so permissive means that extra care must be taken when writing multi-core code – when communicating something to another core (or something like a hardware device which uses buffers located in RAM), barrier instructions must be used to make sure that memory accesses actually occur in the order which they’re listed in the program (leading to quite possibly my favourite instruction mnemonic). “Device” memory is used for hardware devices which are read- or write- sensitive. Speculative reads are forbidden, and all reads & writes to device memory are completed in-order, without any tricks like merging reads or writes of adjacent addresses into one single transaction. However, it’s typical to allow other instructions to continue to execute in parallel, requiring more barriers in some situations (e.g. on modern ARM chips, if you write to a register in a device in order to clear an interrupt, and then re-enable interrupts on the CPU, you need a barrier inbetween the two instructions in order to make sure the store completes before IRQs are re-enabled, otherwise the system will receive a spurious interrupt and potentially crash) |

{kind=link}