Max out VFP performance on the latest ARM cores
![]() 3 posts, 2 voices
3 posts, 2 voices
|
|
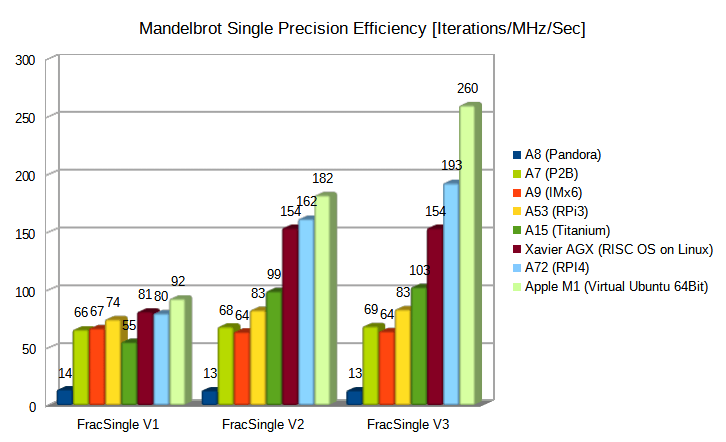
When there’s a new ARM core running RISC OS you might have seen me always checking my old Mandelbrot benchmarks (Link here ) to get some insight in the evolution of the latest ARM cores, especially regarding the floating point performance. Just in the last years when I looked especially at the Cortex A72 (RPi4) results…somehow the performance clock by clock didn’t really enhance compared to former generations even if those cores should theoretically perform somehow better. I was wondering if the way I wrote that benchmark like 15 years ago was generally an optimal way to implement this in Assembler or if it should have been done differently. For your understanding some short introduction to the Mandelbrot algorithm. Some Pseudo-code is here: To implement this in single precision VFP assembler I tried at least to avoid pipeline stalls by making each instructions independent to the next one. That looks like this here (missing the loop exit checks): In my may be naive way I thought that would help the CPU enough to keep the instruction decoder or the usually 2 floating point execution units in one CPU busy enough. It seems I was clearly wrong on this. I guess due to the latency/throughput timings the execution units were still kind of clogged or lets say not used to their full capabilities. But then I remembered some optimisation I did on x86 code that another coder suggested to fully exploit those huge out-of-order windows that modern CPU’s have (also recent ARM cores since may be Cortex A15, but not e.g. Cortex A53, A7, A8, A9. That window is basically an internal table (as far as I get it) where the CPU tries to reorder independent instructions from the flow of code and tries to feed the available execution units as good as possible. Those out-of-orders windows can be as huge as several 100 instructions. For the Cortex A72 it seems to be 128 instructions big. The approach here for such an iterative algorithm is to use as much registers as possible to create as much as possible independent instructions in the code flow. I implemented this by putting a second pixel (so to say the next pixel) calculation within the main iteration loop using totally different registers to the one before: What makes this actually difficult is that you have to implement all the logic that takes care when e.g. pixel 0 diverged or pixel 1 or one of them reached maximum iterations. I leave this to you digging in my source…it gets quite long to handle all of this but works. As I even had more registers left to utilize I even implemented a version for 3 pixels to see if that code is even faster or if I reach another bottleneck or maxed out the CPU already. So in the end I had 3 versions for single precision floating point:
You can download the new benchmarks here The results showing up where more than I could hope for. You can see the graphs normalised to iterations per clock per Mhz in percentage: http://www.mikusite.de/images/FracV1V2V3results.png (…can’t embed the image somehow…any help on this !? I tried some of the differen syntaxes…not success…) While the old approach V1 as I said didn’t gain over all the cores, the V2 begin to fly with the A72 and went up by 103%. The V3 even further to about 142% compared to V1. To pressure the world champion regarding ARM architecture I asked Chris Gransden to run a Linux 64 version of my code on a virtual Ubuntu system on an Apple M1. You can see that due to the 3 instead of 2 floating point execution units the M1 can even benefit further, showing that the approach works and is scalable once the CPU will get more instruction units. The older CPU’s don’t benefit at all from the new code logic. Special thanks go to Raik, Chris and Jan for testing on various devices. I just wanted to share this as it kind of positively disturbed my knowledge how to optimize code for ARM. Depending on what kind of speed critical loop you have, this could be applicable to other algorithms for sure. Non-iterative should be easier anyway. It seems it’s quite time to revisit some of my old codes :-) I also wonder if the latest compilers do help optimizing stuff like that. I also included versions for double precision which performs the same for most ARM cores anyway. Regarding Fixed-Point and NEON the story is different actually. In AArch 32 we only got half of the amount of registers (16) compared to VFP single and double precision (32). I’m still evaluating but it seems much less effective for the Mandelbrot algorithm as you got to compensate with memory access and different flow. Here AArch 64 would help immensely. |
|
|
Yes, things are a lot more complicated than “the old days”. Code, these days, is written by compilers with all sorts of rules for scheduling instructions. I wouldn’t want to attempt to try it manually. You have demonstrated why. ;-) |
|
|
@Rick: Yeah, it’s kind of crazy. When I tested also my NEON variant I ended up with only like +20% for Cortex A72 but actually lost (!) 35% on a Cortex A53…but of course may be for more general code it’s kind of easier to optimized for both. It’s just sad that so much computation power isn’t utilized I guess. As far as I read here, the Apple M1 has an out-of-order window (or re- order buffer) of may be more than 630 instructions…insane ! I guess it’s the only way they can utilize their huge amount of execution units…that window seems to desperately look out for things to be computed so far ahead in the code, most execution units running may be idle a lot of the time :-) |