Chars
![]() 135 posts, 23 voices
135 posts, 23 voices
|
|
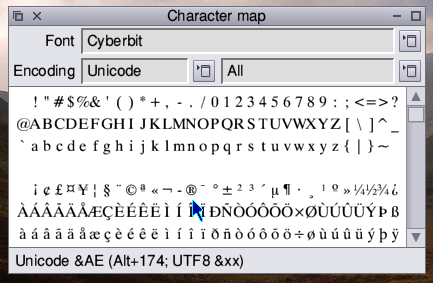
Thanks – that’s helpful. To put things in context, here’s where my current version of !Chars has got (screenshot here). Currently, fonts can be displayed in any encoding, including UTF8, which it defaults to. If the font has an Encoding file inside its own directory, it can also be displayed as a ‘Symbol’ font (Selwyn and Sidney, etc.). Hovering over a character in any 8-bit encoding gives the ASCII character code in the bar at the bottom of the window in Hex, plus the decimal equivalent (to aid in finding the Alt+number combination). In the UTF8 encoding, the Unicode value is given, followed by the UTF8 byte sequence (as you’ll see from the screenshot, I haven’t actually done that conversion yet). In light of Ben’s comments above, it would be easy to restrict the display to UTF8 only. One potential issue with this is that very few people (I guess) will be using UTF8 as their system alphabet, due to the Wimp corrupting menu items, etc., but perhaps that doesn’t matter. Wimp_ProcessKey only transmits >1 byte characters when the system alphabet is UTF8, but I guess this could be simulated by !Chars if needed. The dropdown menu labelled ‘All’ currently does nothing, but is designed to cater for Unicode categories, such as ‘numbers’ or ‘punctuation’. This feature could be achieved by scanning the text file Ben mentions to build a list of glyphs in a given category, depending on people’s views on doing that. As you’ll see from the screenshot, loading a big font like Cyberbit into !Chars gives a very long list of glyphs to scroll through, so having some form of categorisation would make browsing easier. On the issue of having two separate apps – a keyboard-substitute character input app, and a font glyph selector – it’s worth noting that the fonts supplied in ROM only define about 250 characters, so the former would only be useful if that range were extended greatly (which would be nice anyway, of course). My feeling at this stage is that !Chars can probably continue to fulfill both functions if we’re careful about how to handle the way it transmits character/font/encoding information to apps (though I’m happy to be contradicted by those who have a better understanding of the issues). One idea might be for !Chars to transmit a user message with font/encoding/Unicode codepoint information in addition to the UTF8 KeyPressed event, and let applications decide which information they’re interested in – think this was the approach nemo was advocating. |
|
|
I would certainly think that one app would be best, even if it offered two “modes” according to what was needed. Having separate apps could be confusing to users who don’t really understand Unicode (most of them, I’d wager!). One option might be a choices window allowing the user to pick how codes are transmitted – for example, someone making extensive use of Ovation Pro might prefer a native output to that program using the OvPro textstory format, to preserve font selections, sizes and so on… |
|
|
It’s looking good, but I think I’d prefer the status bar to include the standardised Unicode name – in your example it would be U+00AE REGISTERED SIGN It seems to be conventional to use a minimum of 4 hex characters. Some other OSes have very sophisticated mechanisms for searching for specific characters, but it’s not entirely clear to me what primary sources were used for categorising characters in many cases. Two methods that are fairly clear are blocks (e.g. “Latin Extended-A”, “Mathematical Operators” or “Dingbats”) as defined in Blocks.txt and scripts (e.g. “Common”, “Latin” or “Hiragana”) as defined in Scripts.txt. So how’s about this for a suggestion – a two-tier hierarchy for selecting the layout of characters in the window. All the following views would be available, irrespective of the system alphabet.
Then, to reflect the fact that Wimp_ProcessKey only works in the current alphabet, any characters that aren’t supported by Wimp_ProcessKey in the current system alphabet should be shaded. I was very careful with the wording in the last sentence. With the pre-Unicode font manager, bytes in strings painted using symbol fonts were implicitly interpreted as glyph numbers, even though those font managers didn’t support \EGlyph. While this is still the case with the Unicode font manager, it has made a subtle change: if the system alphabet is UTF-8, then the default encoding used to interpret strings painted in symbol fonts is also UTF-8 – so to paint a dingbat from Selwyn, you need to use its Unicode code point, not its glyph number. This can be overridden by selecting the \EGlyph encoding which was introduced with the Unicode font manager. It would therefore seem sensible to mirror this with Wimp_ProcessKey – accept the historical overloading of Wimp_ProcessKey by !Chars for delivering glyph numbers for symbol fonts to applications, but stop doing this if the system alphabet is UTF-8. This would mean that we’re lacking an input method for non-Unicode glyphs when the system alphabet is UTF-8, but that’s precisely what the Wimp message like the ones that have been suggested would provide us with. Something like: R1+20 Flags (reserved, should be zero) R1+24 Glyph number to insert R1+28 X point size * 16 R1+32 Y point size * 16 R1+36 Font identifier, null-terminated This would be sent User_Message_Recorded, and if it bounces back, then !Chars would try again using Wimp_KeyPressed instead:
One other thing that I considered is that for some things (notably the dingbats) the user may wish to choose whether to preferentially issue a glyph insertion or a Unicode character insertion. To facilitate this, I suggest that the Wimp message is only used if !Chars is in the Glyph view. After all, for any font that contains non-Unicode glyphs, that’s the only place you’ll see them anyway. |
|
|
I think the interface I’ve adopted for switching between font views is actually fairly close to your scheme, so I’ll try to finish off the app so people can try it out, rather than make further changes to it at this stage. However, I’d be very happy to take views on board about all of that. I’m not too keen on having a choice between Unicode blocks/scripts in the user interface, though it might be necessary if I can’t figure out a way of presenting useful categories more succinctly. I’ll have a crack at this, and see what I can do. In addition to your scheme for character code/glyph transmission, perhaps it would be useful to add the option that Ctrl-clicks (or Ctrl-Shift while hovering) forces Chars to transmit multibyte UTF8 characters even if the system alphabet is non-UTF8. This would accommodate the possible future case of a Unicode-capable Techwriter/Ovation/etc. being used on a desktop which (for whatever reason) the user prefers to keep working in an 8bit system alphabet. |
|
|
I don’t think mixing alphabets in that way will work. Look at it from the application’s point of view – say the system alphabet is Latin-1, and it receives the two bytes &C3 &A0. These might have come from your proposed extension to !Chars, in which case it should insert the character corresponding to the UTF-8 sequence &C3 &A0, U+00E0 LATIN SMALL LETTER A WITH GRAVE into the document. But equally it might have been caused by the user typing on the keyboard, in which case it needs to insert: U+00C3 LATIN CAPITAL LETTER A WITH TILDE For example, on a UK keyboard, this can be achieved by doing Alt-0,C,3 Alt-Space or Alt-, (dead accent tilde) Shift-A Alt-1,6,0 as well as other combinations. Honestly, a UTF-8 system alphabet is the only sensible choice! :) |
|
|
Ah. I see what you mean :) |
|
|
I agree with Ben that UTF-8 for the input alphabet is the best long-term solution, but we still need a short-term solution. Who would want to switch their system alphabet to UTF-8 at present when it has such varied and unpredictable effects on applications? To take one example, Impact: Impact has its own multi-line writable icon handling. Withe the system alphabet switched, some things would work OK, but caret placement would go funny as soon as anyone tried to step the cursor through a multi-line character. And Impact would quite happily add the first byte of a multi-line character to the display and reject the rest if the field size limit was reached at that point. Problems of this kind, and others, will occur with most other applications other than the very simplest. So if we want to be able to use UTF-8 for Key_Pressed events safely, there needs to be a way for applications to opt in, to say that they are happy to receive UTF-8, rather than having the whole system alphabet switched over. That’s why I was suggesting that the proposed Wimp message be used if the user clicks on a character in Chars which is outside the current system alphabet, to allow it to be passed to a suitably-aware application. I’m not clear, Ben, whether you are supportive of this idea or not? The Wimp message would need a word to carry the Unicode character number in this case. As you have suggested above, if the message bounced, Chars would revert to Key_Pressed events, though if the character was not available in the system alphabet and we weren’t in glyph view, it just would not bother sending anything. From my point of view, as an application author, I would welcome a mechanism like this as it would provide a way for some applications to start supporting Unicode input, albeit of a limited nature (no-one’s going to want to do a lot of input via clicks in Chars, but it’s very useful for the odd character). To make progress with Unicode-aware applications, we either need a Wimp extension so that applications can register to receive UTF-8 keyboard events even when the system alphabet is Latin-1, or we need aWimp message like this to allow users to select characters from Chars and similar utilities. Or both.
Can you point us to where this is? I’ve had a search but cannot locate it. Edit: I’ve now located it ! I’ll have a good read…. |
|
|
I’m just not sure I like the idea of this extra Wimp message, it feels like a fudge. It’s a way to get around a transitional problem, but one which application authors may feel obliged to support long-term. At the least, we’ll probably be fielding questions forever about what the difference between the message and a Key_Pressed event is, whether applications have to handle both of them, etc. To handle a UTF-8 system alphabet, the average application only needs to change the way it navigates forwards or backwards through a string by a character. It’s not a complicated bit of code, and I’ve already posted a link to an example implementation. Yes, if the application has fixed size buffers there’s an extra step to handle the buffer filling up: you can either examine the first byte of the character to see whether it will fit (not hard – UTF-8 is designed so this can be worked out algorithmically without needing a lookup table) or you can delete any trailing partial characters in the buffer each time you get an overflow (possibly only necessary if a continuation byte is being inserted). This is all relatively simple code. And none of this is needed if the application uses writeable icons, as the Wimp handles all that in those cases. I think your proposal is to have a mixture of applications running at the same time, where some applications understand multiple encodings including UTF-8 and others only understand one-byte-per-character encodings, and that the system alphabet (and thus the keyboard buffer, all the strings in the ROM, etc.) and Wimp_ProcessKey remain in Latin-1. In this case, any Unicode-capable applications would need to work in UTF-8 internally, so therefore would still need all the same code to handle UTF-8 text as described above. But in addition to that, they’d need to be able to convert characters of Latin-1 (or whichever alphabet is in use) received from Key_Pressed events into UTF-8. And they’d need to handle the new Wimp message. And their font handling would need updating to set the encoding as well as the font every time a font is selected (it couldn’t just rely on the font manager’s default having changed). I see that as significantly more work, and it would disproportionately affect simpler applications. And after all that, the only way any non-Latin-1 characters can be entered is still by using !Chars. Doesn’t sound like a great way to encourage application authors to add UTF-8 support to me. I think the handicap suffered by applications that aren’t UTF-8 aware are probably overstated anyway. For any text using pure ASCII characters (the majority of text for UK users, at least), behaviour is totally unchanged. Also, remember that most (all?) applications defer the conversion from string indexes to OS coordinates calculation to the font manager anyway. Caret positioning doesn’t “go funny” if the application passes a byte index which isn’t on a character boundary to the font manager, the font manager places the caret at the next character boundary (might be a round down, I can’t remember offhand). As far as the end user is concerned, they just have to (for example) press the arrow key twice to move past a £ sign. And the font manager is designed not to choke if it ever gets passed strings containing incomplete UTF-8 sequences – it displays the Unicode replacement character in its place (though in practice most fonts don’t include that glyph, so you get a zero-width space instead). Plus, I don’t think we should underestimate the ability of the RISC OS community to rally round and update applications if there’s a big enough benefit to be gained. We’ve seen it before, though usually with regards to hardware compatibility. But the changes for UTF-8 are relatively localised, which should limit the work required. And I think that precious engineering time would be much better spent applying a simple fix to many applications rather than a more complex fix (which you could apply to fewer applications for the same effort expended). What is needed, IMHO, is an incentive to get this to happen. You can test an application’s handling of UTF-8 today, by simple use of *Alphabet UTF8 at the command line, and you’ve been able to do this on RISC OS 5 since 2002. If we set a date at which the default alphabet of ROOL ROM images is going to be changed, we might find that application maintainers move to support it in that time frame. It might sound harsh, but I don’t see how else we’re going to make it happen. |
|
|
From my point of view, the fudge has already been around for a long time: Using Key_Pressed events to get characters into applications as if they came from the keyboard when they didn’t. I think there should always have been two methods of input into apps. One for genuine Key_Pressed events, and one for !Chars-like, “I’m sending you some text to put at your caret” events. The two are fundamentally different. Input from the keyboard has modifier keys to worry about, caps-lock, num-lock, etc. The app-to-app “input” that !Chars performs (and we’ve imagined an IME to perform) is something else. Sure it’s a bit of a pain for all apps to have to implement the necessary code to take input from two “sources”, but IMHO the benefits outway the disadvantages. And, as has been suggested by Ben and nemo above, sending a recorded message for the “new” method of input means that the sender can fall back on attempting to send via Key_Pressed if the first message isn’t acknowledged. Perhaps that fallback code could even be automated somehow… Adding a new message now that properly implements app-to-app input (allowing for strings, not just single characters, as I argued above) would to my mind be a useful addition. The Key_Pressed events can carrying on operating as they have done up to now, but the new message could be designed to be much more flexible, as people have already discussed a lot above. It wouldn’t necessarily need to be tied to the system alphabet if it either specified an encoding or passed a known encoding. In the absence of a universal change to UTF-8 in Key_Pressed events and the keyboard buffer, this might be a good thing. So I’m not sure it necessarily needs to be viewed as a fudge, though I can definitely see where you’re coming from with that. And I’m happy to have my mind changed if the arguments are strong enough ;) All the above said, I’d love to see everyone switch over to UTF-8 (or another Unicode variant) across the board, but I can see a lot of people refusing to want to do so if they have some legacy app they like to use that breaks as a result. The only way I can see it happening is if you could control the encoding in which Key_Pressed events were delivered to apps on an app-by-app basis. Then you could set the system alphabet to UTF-8 and revert to Latin-1 (or whatever) for any apps that broke. (A bit like AppLocale for Windows systems – it’s very messy changing the “system language for non-unicode applications” or whatever it’s called – we want to avoid getting into that situation!) But then maybe you’d also need to have similar “hacks” in the Font Manager to control the encoding for these legacy apps, and in the Wimp to control caret movement. Maybe it’s not feasible…
If the above-mentioned ability to revert to the Latin-1 alphabet for a subset of running apps, I think this would be a really positive move for RISC OS. |
|
|
Is Chars 1.22 the current dev version? Seems like a very worthwhile improvement so far. In that version, there seems to be a small issue with repeatedly (5x) clicking on the Font dropdown menu icon – other icons not affected similarly.
The included Hotlist feature could be very useful. Has anyone contacted Martin to discuss things (or pointed him to this thread)? [Edit: remove hyperlink.] |
|
|
No. I haven’t released anything for testing yet, as it’s still very much work in progress. I think I uploaded that old version to my webspace just as a backup, and didn’t post a link to it anywhere (AFAIK). I’m hoping to release a proper test version in a couple of weeks, work permitting. Probably best to hold fire on trying it out until then. |
|
|
Thanks – looking forward to it. |
|
|
Well, there’s !KeyMap, a programmable keyboard driver that supports unicode as well. As a demonstration, you can download the latest version of !Dict, use its Tiny Mode and start typing in one of the 15 supplied keyboard drivers that come with !KeyMap. No doubt, !KeyMap is lacking most of the suggested techniques that are described above, but as a first step, it might encourages others to develop a more comprehensive solution. |
|
|
Really glad you’ve joined this discussion, Paul. I was actually going to email you and point you at this thread. Could you give us some more technical details about how !KepMap passes data to other apps like !Dict? (Presumably a Wimp Message of sorts?) It’d be good to take it into consideration here. |
|
|
Actually, !KeyMap is a front-end to the DKM module, written by Richard Spencer. I’ve really no idea how that module passes data after a key press. Hopefully, Richard will tell us how he did that. Having said that, !KeyMap has its own way of passing data as well, when the supplied virtual keyboard is used . It’s done by the ordinary Wimp_ProcessKey call — a single call in case of a normal Latin1 character, or subsequent calls in case of a unicode character. I suspect, the DKM module works in the same way, but as long as Richard hasn’t revealed the secret, we can’t be sure about that. Anyhow, this superficial technique does the trick, at least for !Dict. Therefore, you should configure !Dict to make it expect a unicode font in Tiny mode. Although the input icon looks like an icon indeed, it is in fact a window, to which the entered text is font_painted. Principally, this could work for other editors as well. It would probably even work for programs such as OvationPro, because the font manager takes care for most of the work as soon as it encounters a \EUTF8 extension. In a DTP program, it would behave almost as a bold or italic extension — if you follow me. However, the technique of Wimp_ProcessKey calls for passing unicode characters unfortunately doesn’t work properly on deeper levels of the WIMP, for example the level that icons rely on. Richard might once investigate how to address that in a future version of the DKM module. Hopefully, this is an answer to your question. If not, I will try to be more clear. |
|
|
To follow up to Paul’s reply above, the DesktopKeyMap module sends multiple UTF-8 codes via SWI Wimp_Processkey regardless of whether the system alphabet is UTF-8. Thus an application need only pass this raw input to Font_Paint with appropriate flags set, and no new message protocol is needed. How it works is by using the FilterManager module. DKM was originally written to allow per-application keymaps implemented via a filter which transposed single Key_Pressed event codes. Paul requested UTF-8 output earlier this year, and this is implemented by the filter ‘swallowing’ the Key_Pressed event, and then the DKM Wimp Task sending the appropriate number of Wimp_ProcessKey SWI’s, which are ‘allowed through’ unchanged. As previously stated, this doesn’t work for writable icons etc. regardless of the system alphabet, simply because the application never ‘sees’ such keypresses, and so neither does the DKM filter code. I’d like to see a full IME helper app with defineable keymaps able to write to icons in the same way as keyboard cut’n’paste utility(ies) work. To this end I am cautious about advocating a new API, and I think it is unrealistic to expect a user to set the system alphabet to UTF-8 when issues remain. (For example, does Wimp_OpenTemplate change Latin1 top-bit-set characters into UTF-8 if the system alphabet is UTF-8? It would be great if it did.) This would pretty much render DKM obsolete, but the keymaps Paul has created are plain text, and could easily be reused by such a program. Aside: I’ve noticed UTF-8 byte sequences in the ROOL sources for the Copyright symbol (C in brackets not being used for some reason). Is this official? See here |
|
|
Thanks to Paul and Richard for providing the details.
Would this not create the ambiguous case that Ben outlined above? Although if via DKM you could specify which apps received UTF-8 and which received Latin-1 (can you?), we’d be halfway to where we want to be.
So would I, and as you’ll see from the above discussion, I’ve got quite a few ideas about this.
This is another thing that would need to be controllable on an app-by-app basis. It probably wouldn’t be that hard to do. Then again, as Template files (and Resource files for that matter) are usually external data files, someone could just write a utility to change the encoding of them if the default system alphabet was at some point switched over to UTF-8. To me, it looks like we should at some point switch the default system alphabet to UTF-8, once we have a utility that can:
What else would need “hacking”? |
|
|
Thus an application need only pass this raw input to Font_Paint with appropriate flags set, and no new message protocol is needed. As far as I understood Ben, he’s talking about mixing alphabets. The approach of DKM, however, is independent of whatever alphabet is set. It just sends the raw unicode bytes to the application you’re working in. It’s the application that has to decide whether the two, three or four bytes are supposed to be a single unicode character or not. Even in a program that can use different fonts in a single document, this doesn’t need to be a problem. It’s just a matter of choosing a font with the \EUTF8 extension, and the font manager will take care for most of the work. There’s no need to provide every single unicode character with encoding information, if the application already expects unicode input. As said, I think this could work for any editor that font_paints text, without lots of modifications. |
|
|
That was unintentional in that case, I think! This sort of thing has slipped through a few times because, ironically, the server on which the sources is hosted has a default alphabet of UTF-8. Fortunately that one’s just in a comment – but it does raise the point that non-ASCII characters in source files are a bad idea in general, since there is no way to indicate which encoding was used for them. The copyright symbol is probably the one that occurs most often in source files. In practice the word “Copyright” has exactly the same legal status, so arguably should be used instead, though obviously it’s quite a lot longer.
The problem is, if you really want to create a bubble in which an application can exist in blissful ignorance of the alphabet in use elsewhere in the system – whether it’s a Latin-1 application in a UTF-8 system or vice versa – then you need to intercept every API which passes string data either way – every SWI, every Wimp message, including all the proprietary ones. That’s a mammoth task, and arguably the effort involved in developing the hacks would be better spent updating all the applications to handle UTF-8 properly. And aiming for anything less than complete interception would end up with quirky behaviour in some cases, so all you’d be doing would be to exchange which quirks are visible to the end user. Here’s an example. If the text in an application’s icons is assumed to be in Latin-1 (say, so the copyright symbol in the ProgInfo dialogue box comes out as expected) then it also follows that any pathnames in FileInfo or SaveAs dialogue boxes, or in the title bar of a document window, must also be in Latin-1, since the Wimp doesn’t know them apart. But under a UTF-8 system alphabet, filenames would naturally be passed around in UTF-8 (particularly from Joliet CDs and long-filename DOS discs, where the filenames are already natively stored in Unicode). So, to ensure that the application never sees UTF-8, you’d have to intercept things such as
And even then, you still couldn’t cope with filenames that contained non-Latin1 characters (say, because the file had been renamed in the Filer). Of course, we’re already living with compromises, since we can’t view or edit filenames from things like Joliet CDs properly at present. It’s only ever going to become consistent once everything uses Unicode. |
|
|
I’ve run up against a slightly odd issue while trying to make !Chars’ font painting a bit more robust. When drawing the Cyberbit font, character &9F98 reliably causes Font_Paint to exit with an error. There are two strange things about this: 1. I don’t know what’s causing the problem: the error message is just ‘D’. I’m wondering if I’m doing something wrong with my error checking/reporting? I think the code is pretty standard; something like: 2. The error only occurs when scrolling down through the font. If I jump right down to the bottom of the font and then gradually scroll up, then the &9F98 character appears as a blank space and doesn’t cause an error. I assume that this is something to do with cacheing. It’s easy to catch the error and skip the offending character, but I’d quite like to know what’s doing it. Ideally, Chars would be able to work around minor faults in a big font (such as the odd corrupt character), while bailing out and reverting to the System font if the whole font is dodgy. Any thoughts? (By the way, would it be a good idea to have a dedicated category in the forums for programming queries like this?) |
|
|
How old is the ROM image that you’re using? A few weeks ago I fixed this bug in the font manager where it was sometimes accessing a null pointer while looking for bounding box info. So it’s possible that my fix fixed the issue, or perhaps my fix caused it to break (or it’s a completely different bug entirely).
That code looks fine to me.
If you can upload or send me a copy of the code then I should be able to get to the bottom of it. |
|
|
Thanks Jeffrey – I’ll tidy it up and send you a copy. |
|
|
Any news on this? |
|
|
Christmas would have been an ideal time to have released some stuff, wouldn’t it? Sigh. I forgot all about it. I will try to get something done this week. |
|
|
Fear not – 351 days to Christmas. Plenty of planning time. :-) |

{kind=link}