Encodings
![]() 106 posts, 18 voices
106 posts, 18 voices
|
|
RISC OS Charset should be ISO 8859-1 It’s closed to Windows-1252 and not ISO 8859-1 as we have some characters between &7F and &9F. In fact it’s not even 8859-1 or 1252 First bug: Second bug: Third bug: But not with RISC OS ones: It’s probably linked to the fact that RISC OS 4 used ISO 8859-15 to solve the euro problem. But today euro is &80 in Windows-1252, so this mix is not needed anymore. Every font should use 1252 by default, as the System font. Let’s conclude: Latin 1 in RISC OS is not really Latin 1 and not really Windows 1252. It’s almost 1252. Latin 9 is used almost everywhere, but not with converted fonts and system font. |
|
|
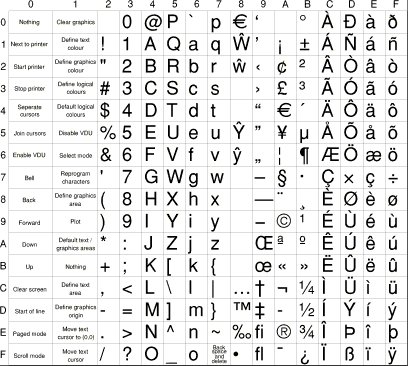
Here is a diagram of ISO 8859-1 from the wiki page:
Pay specific attention to the line in the middle that is just a bunch of dots. The range 128 to 159. Both RISC OS Latin1 and Windows CP1252 are the same as the above character set diagram, with the addition of other characters in the 128-159 range. The problem arises that the additional characters are not in the same places, so additions such as the Euro symbol and sexed quotes will likely appear wrong if written on one system and viewed on another, or if written in either and viewed on a machine with a strict interpretation of 8859-1.
Wrong. There is no euro in 8859-1, and in CP1252 it depends upon the age of the OS as to when they botched it in. Neither euro encoding has any relevance to web documents as it’s interpretation can’t be guaranteed. Use its official code point of
Perhaps, but as you have noticed, 8859-15 is not 8859-1 with a Euro symbol pasted into it. There are other changes, such as the removal of 1/4 and 1/2… When you say the standard RISC OS fonts give the wrong characters, is your system set to Latin1 or Latin9? If Latin9 then that is correct and as expected. If Latin1 then that is wrong and broken.
Absolutely not, otherwise the sexed quotes in every single DTP document will be wrong. The RISC OS implementation of 8859-1 works for RISC OS, end of. [of course, if the Wimp properly supported UTF-8 since forever ago, we probably wouldn’t be having this discussion ☺] In summation:
|
|
|
Yes, there’s nothing much to add to Rick’s response, except to stress that the “Latin1” encoding commonly used on RISC OS is not 8859-1, but a superset. From a PostScript point of view it is Acorn_Latin1Encoding, which is distinct from ISO_8859-1Encoding or Adobe_ISOLatin1Encoding. The encoding tells you what character to expect for a particular codepoint. However, a font can produce any shape glyph for a particular codepoint, by accident or design. Even the RO system font – BFont – is not definitive, as VDU23 will attest. BFont exists to satisfy more requirements than simply matching 8859-1, and in fact is a superset of Acorn Latin1 itself, as it has some Wimp symbols in it. Although unintuitive, one cannot expect every character in BFont to be available in every ‘proper’ font. I am still in the process of producing a Unicode version of BFont, which currently comprises over 28,000 glyphs – more than the vast majority of RISC OS outline fonts. It would be a mistake to expect it to match your installed fonts too! What your keyboard emits in response to a particular key combination is at the whim of the keyboard driver designer. I have written many keyboard drivers. This one emits the trademark symbol ™ if I press Alt-T,M – is that ‘wrong’? Depends what you were expecting. I believe the current RO5 drivers go through Unicode, so this is just a restatement of your first misunderstanding. Lastly your identification of codepage 1252 is particularly wrong:
The system font is a superset of Acorn_Latin1, it is quite different from CP1252 in the C1 range as Rick has described. It is perfectly possible to have CP1252 as your system font, as I shall demonstrate:
But not as standard. You’d need the CerilicaAlphabets module, or equivalent. |
|
|
Rick pouted
Yeah, sorry, I’ve been busy. I am actively working on it. I have UTF-8 at the command line with transparent Latin1 fallback. I’m working towards a release, but it needs VectorExtend too really, and that was seriously out of date. My recent work on ‘the relatives’ is part of getting that up to date (and that’s a lot more complicated than the UTF-8 support really). |
|
|
I am really looking forward to this. Many, many thanks for your efforts! |
|
|
With HTML5, glyphs and encodings are at the same level: “legacy support, do not use”. Both.
I know, but it was used in ROS4.
It’s a stock OS. Some fonts use strict ISO 8859-1 (the System one), some other use ISO 8859-1 with extra caracters (the converted one), and others use 8859-15 (the Acorn fonts). On the same system, at the same time. That’s where I see a problem. Why Ctrl+E issue a &80 euro (8859-15) when it should issue a &A4 to suit the Acorn_Latin1Encoding? And why at the same time I do not get a euro in a taskwindow, just because the system font uses the Acorn_Latin1Encoding? I don’t understand why the codetable changes with the font used.
I know. With 8859-1/Windows-1252 I mean ‘this strange mix of ISO 8859-1 + Windowish extensions, almost the same as Windows 1252’ (only two major changes). AKA Acorn_Latin1Encoding (thanks Nemo for the precision).
OK, OK, I mean, that RISC OS should use the same encoding all the time. Today, that’s a nightmare when you copy paste thing, or change the font. I write a € with Trinity under Draw, change it to FreeSerif, and – magic! – no € anymore, but international currency sign. I do not change my configuration and do not change my text.
That’s why I post in “Bugs”, as I use the stock French driver. My explanation is a bit blurry, but the 3 bugs remain: *In Chars, System Font says that some characters are not defined, while there are (dixit StrongEd). *Alt+E on keyboard gives me &A4. That’s an error, since &A4 is Euro… in 8859-15. In Acorn_Latin1Encoding it should be &80. *Default encoding of fonts can vary. With System font, &BD,&BE typed in Draw is 1/4 & 3/4 : ISO 8859-1. The same with most converted fonts. But not the same when I switch to stock Acorn fonts where ISO 8859-15 is used. Just try, you’ll see. |
|
|
Sounds like a bug in the keyboard driver you are using. The default “German” keyboard gives &80 on both RISC OS 4 and RISC OS 5 (just tested on RPCEmu 0.8.15). The question is: why do you see an Euro symbol on &A4 at all? All standard fonts I skimmed with !Chars have it only on &80. I dimly remember a cock up in early RISC OS 4, maybe I fixed my RO4 “emulator” disc image? |
|
|
I confirm: it’s a bug. So my message.
That depends of the codetable used in Chars :) |
|
|
Of course. Because they think the entire world is going to instantly discard millions of older content and switch to UTF-8. Well, you know what? Encodings will be around for the foreseeable future, as will sites that use frames. Hell, we’ll probably be shot of flash first. (here’s hoping…)
So were rounded buttons. As Mr. Glover hints at in another thread, there is virtue in sorting out the mess of the disparate versions of the platform (only do not even touch the cluster**** that is GPL with the broken end of a mouldy broomstick); however reality isn’t like that.
First, which version of the OS? You mention RISC OS 4. Your system has an Alphabet setting. This is likely going to be Latin1 for most of us English speakers, maybe Latin9 for RO4 people, and UTF-8 for the adventurous. When in Latin9 (8859-15), your 1/4 and 1/2 should be replaced with an oe ligature in upper and lower case, plus some of the lesser used punctuation will have been replaced by an S and a Z (both cases) having an upside down hat on it (a “caron”, the two characters mostly being used in Slavic languages).
Keyboard driver brokenness coupled with confusion over whether to place the Euro at &A4 instead of the generic currency symbol, or at &80 in the technically undefined area of 8859-1 that was, actually, used for stuff in RISC OS – it is a tick. Does the Desktop still use this if working in VDU font mode? The end result of this, by the way, is nicely illustrated by this character set diagram from riscos.com that has the Euro symbol in both positions:
8859-1 was published in 1985. Both Acorn (in ‘86) and Microsoft (probably also then) adopted the basic layout of 8859-1, and added some extra stuff into the blank spaces. Neither is a clone of the other. They’re both 8869-1 with additions.
This is because the Euro symbol was added into Latin1 in two different places. Probably what needs to be done is to pick one and say “it’s there, the end” otherwise you’ll need to put up with this mess. But hey, you’ll need to get it fixed quickly because Brexit. :-p
How is StrongEd rendering the text? If it’s anything like Zap, it wouldn’t be too hard to have an entirely different encoding to the OS – I have had Zap in PC-ANSI mode (with the faux serif characters and all).
Keyboard driver will need fixing to emit the correct code (my vote is for &80).
What do you mean? When you change to Latin9 the encoding is different? Uh, isn’t that what’s supposed to happen? |
|
|
The style guide lists both “Heavy check mark” and “Euro sign” at &80 (and not at &A4). It notes that the Wimp doesn’t use the Euro character (which implies that the tick may still be used somewhere). |
|
|
The problem david is that you keep comparing a branch of the OS that will never get anymore development, the only reason I can see for Arron buying that branch of the OS is to safeguard the sale of his Emulator. Future development would have to be limited to that product not the existing old out of date hardware. |
|
|
It’ll be fun converting all my web content to UTF-8 – but oh, so worth it, and not that hard: a BASIC program to do it won’t be that hard to write. I don’t think it would be feasible to write it in such a way that it would help anyone else though: I’ll take a lot of advantage of knowing how my content is structured. |
|
|
As said: RISC OS 5.
As said: stock ones, Corpus, Homerton, NewHall, Sassoon, Trinity.
I never changed this.
System font. The problem is that Chars do not print a few characters, œ for example, but there are defined in the system font (or not, if StrongEd use its own system font. I did not check this).
Yes, I agree.
No, I do not change anything! I repeat again: I open Draw. I write ¼ ½ in System Font with the help of Chars. I switch to FreeSerif: still OK. I switch to Homerton, and I see Œ œ. The system changes the encoding for Acorn fonts. It’s not Acorn_Latin1Encoding any more, but 8859-15. I do not use RISC OS 4. But I have the sensation that as RISC OS 4 used ISO 8859-15 for its stock fonts (excluding the bitmap system one), perhaps that they broke something at that time to make Corpus, Homerton, NewHall, Sassoon, Trinity using 8859-15 while the other parts of the system are still in Acorn_Latin1Encoding. Both at the same time. That’s not an explanation. Just a suggestion of what happens. That would implies that this bug is not in the kernel, but due to a bad encoding trick in Acorn fonts.
I agree, so there is a bug in the stock French keyboard driver.
One more time, I do not compare anything. I saw bugs on RISC OS 5. But I think that perhaps there are linked to the fact that the Acorn stock fonts where changed for RISC OS 4 and its strange mix of Acorn_Latin1Encoding + ISO 8859-15. When I print &bc with Homerton, I should get the same character as with System font and other fonts: ¼. But I have another character: Œ. That suggest that Homerton use Latin 9 while my configuration is Latin 1. Or that other fonts use Latin 1 while my configuration is Latin 9 :)
I have one. But it’s such a pleasure to edit, save, send to ftpc with just one version of a file. Today, for HTML, I use 8859-15, as it’s closed enough to Acorn_Latin1Encoding. Just a few things to swap with Chars. Acorn_Latin1Encoding → Windows 1252 is a no go. Chars do not have CP1252, so I have no way to find easily the good character. |
|
|
Sadly, I have a lot of glyphs on my webpages, because I use much too wide a range of characters for 8859-15 (Russian, Hindi, you name it). My pages date from various periods and vary in what they use, but I’d like to standardize them, and then they’ll be UTF-8. I write most of them on the Mac these days, but used to use mostly a PC. But if I do massive editing of the kind I’m envisaging at the moment, that will be on the Pi, using BASIC. |
|
|
Corpus, Homerton, NewHall etc are Acorn vintage items and pre-date the ROL involvement of RO4.02 |
|
|
Okay then. Don’t complicate the issue with RISC OS 4…
Enter When you use fonts, it does not look like this?
I don’t see that here – I just tried writing something in Homerton using Chars in system font. The same characters appear.
It is my understanding that both incarnations of RISC OS began from the RISC OS 3.8 codebase and pretty much went their own way from there.
Just tried with !Draw again. If I change the alphabet, the font changes. Hmmm…
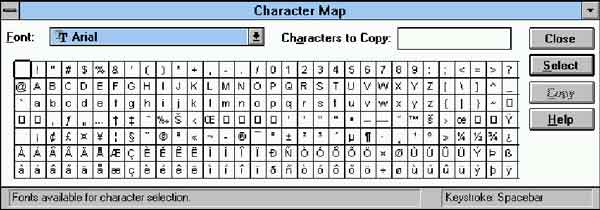
:-) Look at the above !Chars screenshots. See it is seven rows of characters? The one in the middle (that may or may not begin with € and ending with ‘fl’)? Ignore that row. My blog claims 8859-1 and provides everything >127 as a named glyph (if normal known character) or an &#…; code for Japanese and stuff. This -> ☺ <- is written as ☺… For what it is worth, I write much of my HTML in Notepad++ on Windows, so it’s a simple case of selecting a block of text and a keypress (Ctrl-E I think?) to encode all of the characters as the correct glyph. I ought to see if I am smart enough to make Zap do that… or can it already? Encodings are a problem. That is why I am pushing so hard for you to use glyphs. UTF-8 is difficult on RISC OS, so using an encoding makes more sense for us, but clearly the encodings are not interpreted in the same way. One must not lose track of the fact that the desire to interpret 8859-1 as CP1252 makes zero difference to the majority, but it makes a big difference to RISC OS; but Acorn’s Latin1 is not quite the same as either 8859-1 or 1252. Again, the use of glyphs glosses over all of these problems. I used to write text using plain characters, but when “›uf” (oe) comes out wrong elsewhere, and ”sexed quotes•, the ˜ em dash, and bullet points don’t look right on other platforms, one learns rapidly to use named glyphs instead of just writing stuff… |
|
|
nemo:
Your Twitter image does not work. On iOS/Android, it appears as a broken image, and on NetSurf (RISC OS), it pops up a demand to log into ton.twitter.com. Use imgur.com, it’s simpler… |
|
|
No, in fact that’s problably the only point where I was right :) That’s the French keyboard module that switchs to 8859-15 / Latin 9, as on RISC OS 4! That’s why you don’t have my problems (you’re in Latin 1). With Alphabet Latin1, all is OK: Encoding of Acorn fonts and the char code sent by AltGr+E (&80) are consistant. The problem is just that the French keyboard should stay in Latin 1 and not switch to Latin 9. Here is the first proposal. Then you’re in Latin 9, there is a bug: all Acorn Fonts switch to Latin 9 (not the system one, see below), but some fonts converted with TTF2f stay in Acorn_Latin1Encoding (while they can be printed as Latin 9 in Chars!). So in fact that’s not RISC OS fonts that are rotten… but some others. So the real bug here is in TTF2f. This one was really hard to figure out. The System font issue is more complex, and three parts. 1/ I’m booting in Latin 9 (thanks French keyboard driver). In Chars with System font, char &A4 should be tick (AKA Euro) and not international currency anymore. &BC and &BD should be defined as Œ and œ as they are not ¼ and ½ anymore. Conclusion: the charset of System font is fixed, whatever the alphabet choosen. But there is a problem with this: then you use Latin 9, if you type &BC, you’ll get ¼ with System font (Latin 1) and œ with all the others (Latin 9). A nightmare when you switch between Edit and Writer. You see the problem? 2/ Fixed encoding? Not really. In the same time, characters of System font between &8C to &9F are seen as “not defined” in Latin 9. And it’s true, as it’s 8859-15 specific chars, not present in the font. So System font is always Acorn_Latin1Encoding, but not for characters between &8C and &9F. If we must do the things the bad way (for a good reason probably), let’s do them fully: keep the whole as Latin 1. 3/ The problem with StrongEd is that he uses Latin 1 all he time. And so print the ‘not defined’ caracters of the System font while in Latin 9 context. You can even copy them after in Edit. So it’s a ‘bug’ in StrongEd, that thinks that you’re always in Latin 1. There are so many issues with non Latin 1 alphabets (fonts, apps, etc.) that I suggest to switch all keyboard drivers to Latin 1. In the meantime, I put an ObeyFile with “Alphabet Latin 1” in my boot sequence, and it’s much better than before. |
|
|
Netsurf too (a bug). The browser see glyphs as words. So Résultat can become I would prefer to use glyphs, but I can’t because of this bug. I tried Latin 1, before understanding that it was not CP1252. |
|
|
Yes indeed. My web pages are like that throughout because it works. But I’d be perfectly happy to change them all to UTF-8 if that worked and seemed to be the future. |
|
|
The system font does change, it’s easy enough to prove, however that’s all by the by. If the fact is the keyboard driver is changing things like that… the driver will need to be looked at for it shouldn’t be mucking around with the system language, surely?
I think ZapRedraw may be the same. Back when this stuff was written, nobody really thought much about anything like other encodings?
NetSurf is broken, a word shouldn’t be split in the middle just because there is a glyph, but I’ve seen ending quotes on the next line so there’s something odd in the rendering anyway. Still, the benefits of using glyphs outweighs the oddities of one browser. ;-)
Me too, if we had an editor that coped well with UTF-8. |
|
|
Easy enough to write a couple of little BASIC apps that translate back and forth between named glyphs and UTF-8… and I expect you touch type &namedglyph; as automagically as I do… I don’t half miss the easy creation of keyboard drivers that I used to have with IKHG, so I could switch between touch typing in English, Hindi, Russian and Greek at the click of an icon…in those days I had glyphs for those mapped onto the top-bit-set half of 256 character fonts (yuk – but it worked) but nowadays they could issue named glyphs or UTF-8…but I don’t have a functional IKHG any more… |
|
|
Back home now, so the above picture will work. ;-) Hmmm… *Alphabet Latin1 *Keyboard France *Alphabet Latin1 *Keyboard UK *Alphabet Latin1 * Clearly not the keyboard driver. <rummage…rummage> Ah, found it. It’s the French territory module. I presume it is doing that to have access to the Euro at &A4 (no other reason to specify a different encoding as French is perfectly well covered by Latin1), though this is now somewhat outdated as Latin1 has the Euro at &80 (as loading !Chars will indicate). Okay, I’ve just done a quick hack to see if this works okay. It now specifies Latin1, and the currency symbol as &80 (as it appears in front of me in !Chars in System font, Corpus, Homerton, and Trinity). That is technically an unofficial position, as only Latin9 (8859-15) has a defined place for the Euro, however the Latin1 position is the same as Windows CP-1252:
Here’s my quick hack: http://heyrick.ddns.net/files/feugeyfrancefixed.zip It is built standalone, so I presume you’ll want to load it before anything else… |
|
|
Why Latin9 for France? Spain, Italy, Germany, Ireland, Denmark… all use Latin1 and &80 as the currency symbol. Listed as a potential bug: https://www.riscosopen.org/tracker/tickets/449 |
|
|
All that history at school, years living there in France and you don’t know? Didn’t we sort of cover this when discussing keyboard layouts and the existence of a prime key in the layout for an accented character that is used in something like one word? |