Findings on Memory Speed on the BB
![]() 10 posts, 3 voices
10 posts, 3 voices
|
|
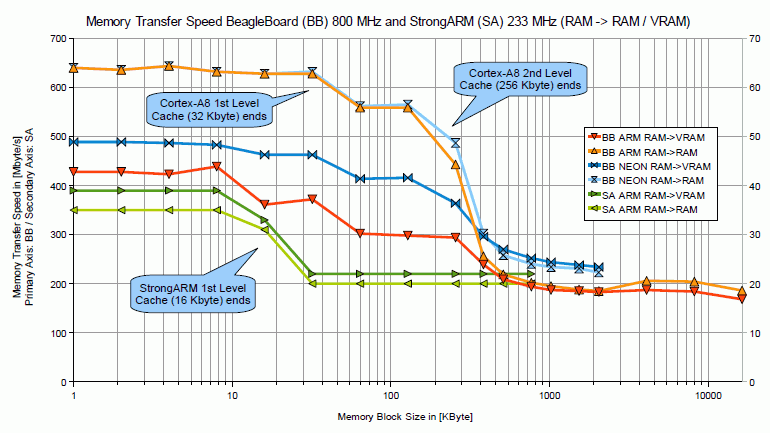
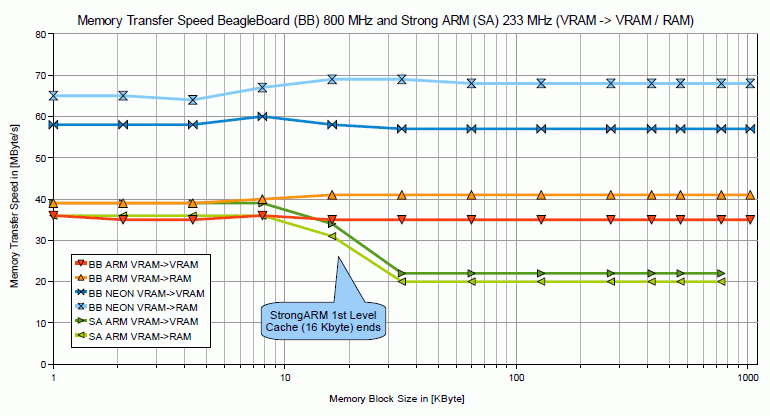
Hi there, while playing around with ARM NEON on the BB I thought it might be of a benefit to find out if that part of the CPU also could improve memory transfer routines, as it offers VLDM/VSTM instructions using up to 16 double word registers (Dx). One could also use quad word registers, but according to the TRM’s of the Cortex-A8 that would be assembled also to Dx anyway. So I wrote a benchmark for transferring different amounts of memory blocks for the following source and destinations: VRAM → VRAM As I’ve already seen in my Firebench compared to the StrongARM the BB is much faster regarding memory transfer. So I wanted to see what figures can be reached for the transfer rate using old school STM/LDM and compared that to the ARM NEON commands. Therefore I wrote !MemSpeed" to measure the transfer speed in [Mbyte/Second]. More details about the code in the ReadMe file. I compiled my findings in the two following graphs: Please note that in the first graph there’s a primary axis for the BB and a secondary axis for the StrongARM, as the StrongARM is (depending on the size of memory block moved about 10 to 32 times (!) slower than the BB, when it comes to RAM → VRAM or RAM → RAM transfer. On the other side one can see that basically all transfers from VRAM → RAM/VRAM are more or less equally slow. But in the real world those transfers are not used very much anyway. Regarding the effect of the NEON unit, it can be seen that it can be beneficial. RAM → VRAM transfer can be up to 40% faster and also RAM → RAM can be up to 20% faster. Even if I couldn’t reproduce the exact the findings of similar tests on the BB from here Link, I think it’s really worth a try for all memory copy intense applications, also may be stuff like a Web Browser, to experiment with NEON routines. One more hint is to use the PLD (PreLoadData) instruction. I didn’t find it beneficial in all circumstances, but from the former link and also partly my experiments it looks like there’s even an additional benefit for that. Although the parameters for PLD look like kind of “try and error” for me. As usual any comments welcome… |
|
|
Very interesting! Thanks for this research. The first thing that springs to my mind is screen block copies. Could they benefit from this? |
|
|
…I think so. Just as far as I know, the support for NEON isn’t there yet totally on Risc OS/BB, also not totally for the GCC (though Terje did some work to be able to include !ExtASM files into GCC), I suppose and what I would think most people use for software developement. But I hope it’s encouraging people working on NEON support, because there really seems a lot of benefit, of course not mainly regarding memory transfer :-) |
|
|
Interesting how the NEON VRAM → VRAM copies are so much faster. Maybe it’s because each transfer is bigger, so there’s less of an impact from setting up the SDRAM accesses.
Screen block copies (assuming they go via GraphicsV) already use the OMAP’s DMA controller. According to some old notes of mine that gives them a transfer speed of about 120MB/s… apart from left-to-right copies which can be as slow as 3.5MB/s! Plus the smallest transfer unit the DMA controller supports is 1 byte, so 1/2/4bpp transfers will often fall back to a software copy routine (which would get around 40MB/s). So there are a few things that could do with happening:
Any volunteers? ;) |
|
|
I would like to help, just I don’t have a clue on OS programming…but if someone gives me a piece of assembler to convert/optimize it with NEON, I’m glad to give it a try…are the kernel software in C or ASM ? About the DMA for screen block copy, how can this be used, is there any software example somewhere ? |
|
|
The kernel is assembler.
There’s some basic documentation for GraphicsV here. You’re interested in reason code 13 (render). Here’s a quick example: DIM block% 24 block%!0 = src_left% block%!4 = src_bottom% block%!8 = dest_left% block%!12 = dest_bottom% block%!16 = width%-1 block%!20 = height%-1 SYS "OS_CallAVector",1,1,block%,,13,,,,,&2A Note that if hardware acceleration isn’t available, nothing will happen; it’s down to the caller to implement his own fallback routine. For kernel code which makes use of GraphicsV 13, take a look at:
RectangleFill and BlockCopyMove are probably the only two worth looking at – unless you’re redirecting to sprite it would be highly unlikely for FastCLS or TryCopyScreenUp to fail to use DMA. Good luck! :) |
|
|
Also note that when calling GraphicsV, 0,0 is the bottom-left of the screen, the units are in pixels (not OS units), and it’s expected that the rectangle(s) have been properly clipped to the screen size. |
|
|
Thanks for all the insight ! I finally looked a bit into the ‘vdugrafd’ and ‘grafa’. Regarding BlockCopyMove I found it strange that it seems to use either a 7 word copy or a 1 word copy routine as a workhorse. I always thought an 4 or 8 word thing is faster. Also there’s a command called like “ShiftR R6,R7,R3,R4”…did I miss something, or what is that kind of instruction ? Anyway if (you ;-) (?)) want to give it a try it should be straight forward to change the 7 word copy routines to a 8 word VLDMIA Rx!,{D0-D3}/STMIA Rx!,{D0-D3} and adjusting the counter from 7 to 8….but I guess it’s still a problem finding an Assembler/Compiler to assemble the kernel with NEON as there’s only !ExtASM doing it !? Of course I see not so much of a point if GraphicsV is used anyway. The question for me is for example if any web browser or graphics software uses any of these routines or they copy lots of memory ‘by hand’ ähh ‘arm’ ;-) with their own code…then the benefit could be only made by adjusting the application code itself for NEON or GraphicsV. |
|
|
Yeah, that does seem a bit odd. Maybe they just never put much effort into optimising it.
That’s a macro – see Kernel.s.vdu.vdudecl for the definition.
I think the best way to test out any changes would be to create a testbed program containing a copy of the kernel code and a copy of the new NEON-enhanced code. That way the interested people (i.e. you ;-)) can easily debug and optimise the code without worrying about objasm’s lack of NEON support, or having to build new ROM images all the time.
I suspect that most desktop software (or at least all the well-written stuff) simply uses Wimp_BlockCopy when copying/moving/scrolling/etc. Since Wimp_BlockCopy relies on OS_Plot 190 to do all the copying/moving, this means it should end up using GraphicsV whenever possible. |
|
|
Hm, if most software uses Wimp_BlockCopy it’s a little disencouraging…as it seems hardware accelerated anyway by GraphicsV. Just, I thought the RAM to VRAM transfer is also used a lot by desktop software like browsers and image processing / drawing software. And that would benefit quite well from NEON. Or is there also some hardware accelerated routine for this kind of memory transfer ? In other words, is there a DMA copy routine from RAM to VRAM ? |